The Rapid Rise of GenAI: A 3-Year Journey
On November 30, 2022, OpenAI released ChatGPT and kicked off the hype around generative AI. A machine learning model this powerful had never been made publicly available on this scale before. The chat interface was super user-friendly and made it easy for a large, non-technical crowd to interact with AI in a natural, intuitive way. A few months later, it became the fastest-growing consumer software app in history, hitting over 100 million users. These days, everyone’s talking about GenAI. So, to be part of the conversation, let’s dive into what these models are all about and where the technology is headed.
ChatGPT is based on a large language model. Large because nearly the complete content of the internet was used to train the model. For the sake of simplicity, let’s describe LLMs as a sophisticated sequence of word predictors (Anthropic provides a helpful article explaining how LLMs work; see reference 1). For example, given the prompt “The Eiffel Tower is in”, the model will likely predict “Paris”. These predictions even worked on larger, more elaborated prompts and can produce more sophisticated, longer text answers. You’ve probably tried one of these models and noticed they seem to reason like humans. However, LLMs barely “understand” the semantics and complex relationships of the things in our world. They produce text by recognizing patterns. Somewhere in the training data, those words often appeared together, so the model now combines them in the response. The real challenge here was to gather all the data and the extensive cleaning required to make it work. Otherwise, these models might suggest eating pizza with glue or other strange ideas just because someone mentioned it on Reddit. This actually happened with one model trained by Google. It fell into the trap of bad training data. It shows how important it is to give the models the right context and data. Context is king.
Even with clean data, these models have three main issues: their knowledge gets outdated quickly, they are only trained on public data, and they generate false but believable information (hallucinations). To get real value, many companies need to use these models on their own proprietary data and increase their reliability. But training such models is a long, costly process that requires significant technical expertise and a lot of computing power. To tackle these challenges, a method called Retrieval-Augmented Generation (RAG) was introduced.
RAG enhances LLMs by retrieving relevant information for the LLM before it is answering a user’s question. RAG systems usually embed text chunks as vectors in a database and use similarity searches to find relevant chunks. These methods improve accuracy, reduce hallucinations, and enable models to answer questions based on your company’s data. It is also easier to implement, at least in its basis form. In the picture underneath, you can see a typical RAG workflow. It usually consists of the following steps:
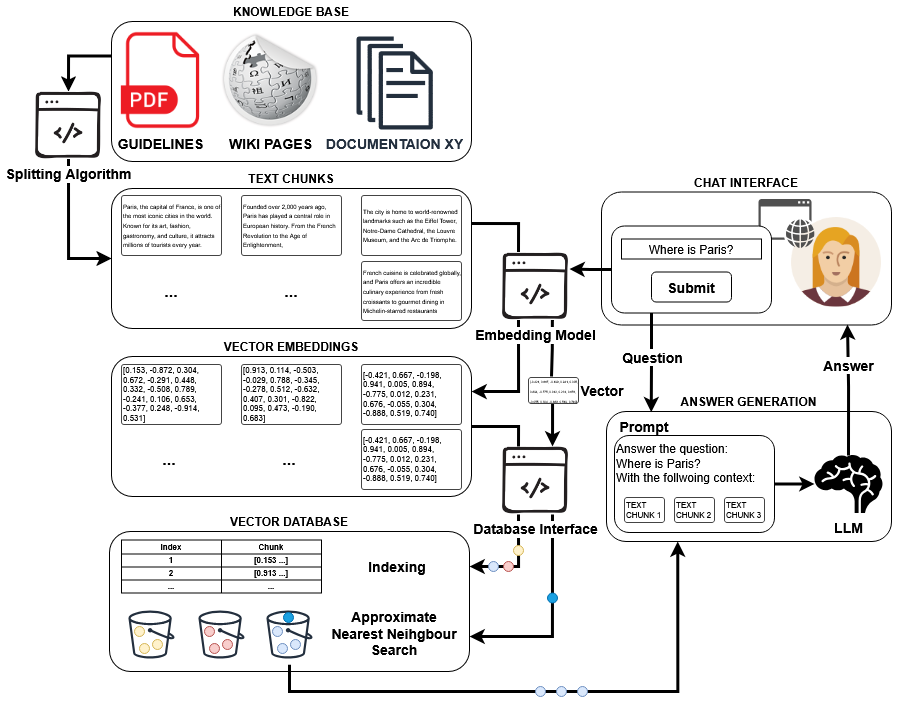
- Text Chunking: A splitting algorithm processes the documents from your knowledge base and breaks them into smaller text chunks.
- Embedding Generation: Each text chunk is passed through an embedding model, converting it into a high-dimensional vector representation.
- Vector Storage: The resulting vectors are stored in a vector database alongside their corresponding text chunks, with indexing for efficient search.
- User Query Submission: A user submits a question through the chat interface.
- Query Embedding: The query is passed through the same embedding model to create a vector representation.
- Similarity Search: This query vector is used to perform a similarity search in the vector database to find the most relevant text chunks. Different Approximate Nearest Neighbor (ANN) search algorithms can be used here.
- Prompt Construction: The retrieved text chunks are combined with the user’s question into a prompt format.
- Answer Generation: This prompt is sent to a language model (LLM), which generates a natural language response that will be returned to the user.
So far, so good. However, providing the right text chunk or context for a given task has proven tricky, but it is the key to getting reliable results. Remember: context is king!
As the next step in the evolution, knowledge graphs emerged as a promising way to provide more fine-grained and accurate context. This trend was driven by two main factors: LangChain’s support for Neo4j and a study published by Juan Sequeda. LangChain has been and still is the go-to library for building RAG applications, while Neo4j is one of the leading graph database providers.
Patterns like Parent Retriever or Hypothetical Question made it easy to get started with GraphRAG and offered some quick wins. However, most of these approaches still relied heavily on similarity searches over text chunks, rather than fully using the querying power of actual knowledge graphs.
The study by Juan Sequeda and his team showed that LLM accuracy can improve by up to 50% when context is supplied through a knowledge graph. Fun fact: Juan Sequeda is the Chief Scientist at data.world, a company that sells knowledge graph solutions. So yes, there might be a bit of a conflict of interest, but in my opinion, the study is scientifically solid. Therefore, the choice between vector databases and knowledge graphs significantly impacts the ability to provide relevant context, and we know context is king.
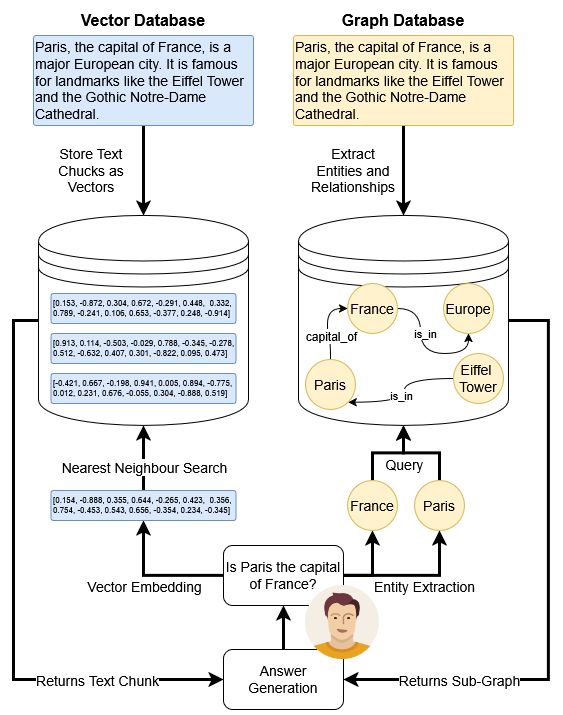
Vector databases represent information as high-dimensional vectors, enabling the retrieval of semantically similar content. For instance, if a user asks, “Is Paris the capital of France?” a similarity search might surface a sentence like the one provided in the picture underneath based on how closely the text matches the query in vector space. These results are then added as context to help the LLM generate a more informed response. However, the chunks of text stored in vector databases are often large and may contain irrelevant information, which introduces noise and decreases the precision of the output.
In contrast, knowledge graphs structure information into discrete entities and their relationships, offering a more precise and interconnected understanding. When a user inquires about Paris, the system can identify the “Paris” entity and directly retrieve related nodes, such as “France”, “Eiffel Tower”, or “Notre-Dame Cathedral”, along with their associated attributes. This structured approach allows the system to deliver more targeted and contextually rich answers.
Even though these approaches are well known in the community, they aren’t widely adopted. Personally, I believe knowledge graphs are still quite complex to implement, and only a few data leaders actually use them effectively. Most knowledge graphs are built on the semantic web stack using RDF and OWL. These technologies are tough to grasp and, so far, have mainly been popular in academia and the biomedical domain. I guess those fields value efficient data sharing with rich semantics. Most RAG applications today still rely on vector databases because they’re just simpler to work with.
Fast-forward to the new term dominating the news: Agentic AI. Experts, or those looking to make money, claim that in 3 to 6 years, AI systems will be able to autonomously plan, reason, and take actions with minimal human intervention. So, what exactly is an AI agent? I like the definition Damien Benveniste provided in a LinkedIn comment:
“Agentic AI can include humans in the loop (human agents). Agentic AI is a paradigm of building software involving multiple AI agents, including human agents if needed. AI agents have existed since the beginning of AI. They can be rule-based, planning agents, reinforcement learning based, and, more recently, LLM-based. They are not defined by instruction-following capability but by agency capability. They make decisions based on how they were designed.”
Instruction-based AI is what we’re familiar with from chatbot interactions. You provide an instruction, and the chatbot generates an answer. Agentic capabilities, on the other hand, are defined by a certain degree of freedom to make decisions on how to solve a task. For example, an AI agent could book a flight to Paris by comparing prices, checking schedules, and confirming details without needing manual input at every step. While high autonomy might seem ideal, it’s often more practical to limit the agent’s freedom to prevent unpredictable behavior.
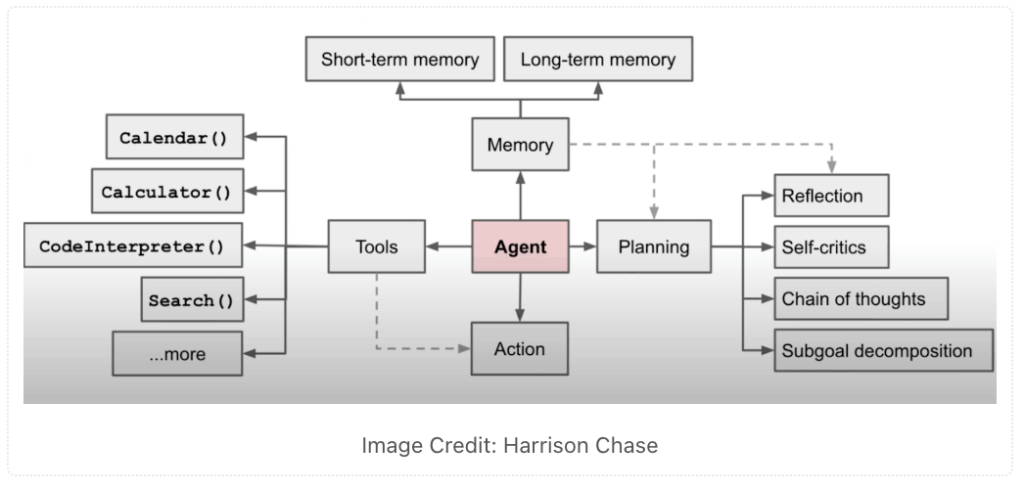
An LLM-based agent typically consists of the following components:
- Planning: An agent breaks tasks into smaller, manageable steps, analyzes them, and determines the best approach. Commonly used patterns are chain-of-thoughts and tree-of-thoughts.
- Memory: Agents can use different types of memory, such as short-term memory to track ongoing conversations and ensure coherence, as well as long-term memory to retain information over a company’s knowledge base.
- Tools: The integration of tools enhances AI agents by equipping them with capabilities to perform tasks, such as managing calendars, performing calculations, or searching the web.
- Action: Agents decide in which order action should be executed to process a given task and use the provided tools effectively.
The Agentic AI community is still figuring out how to design individual agents. There are no established best practices yet, and everything remains fairly fluid, so major updates to frameworks can be expected and will hinder adoption for consumer-centric applications.
However, the next evolution is already on the horizon: multi-agent systems. In these systems, multiple AI agents with different purposes should collaborate, much like a human team.
Imagine booking a holiday to Paris. You would need a travel coordinator to oversee the entire trip, a flight agent to evaluate the best flights, a hotel reservations agent, a public transport planner to arrange airport transfers, and an activity agent to book tours or event tickets.
In this system, the travel coordinator agent might use a “Plan-and-Execute” method to create a series of steps: gathering your travel dates and preferences, sharing them with the flight agent, reviewing flight options with you via a confirmation agent, passing your stay details to the hotel reservations agent, and then assigning the public transport and activities agents to finalize transfers and tours. At each step, a different specialist agent takes charge, using dedicated planning and booking techniques. This setup, where specialized agents communicate through a central travel coordinator, is called a supervisor pattern.
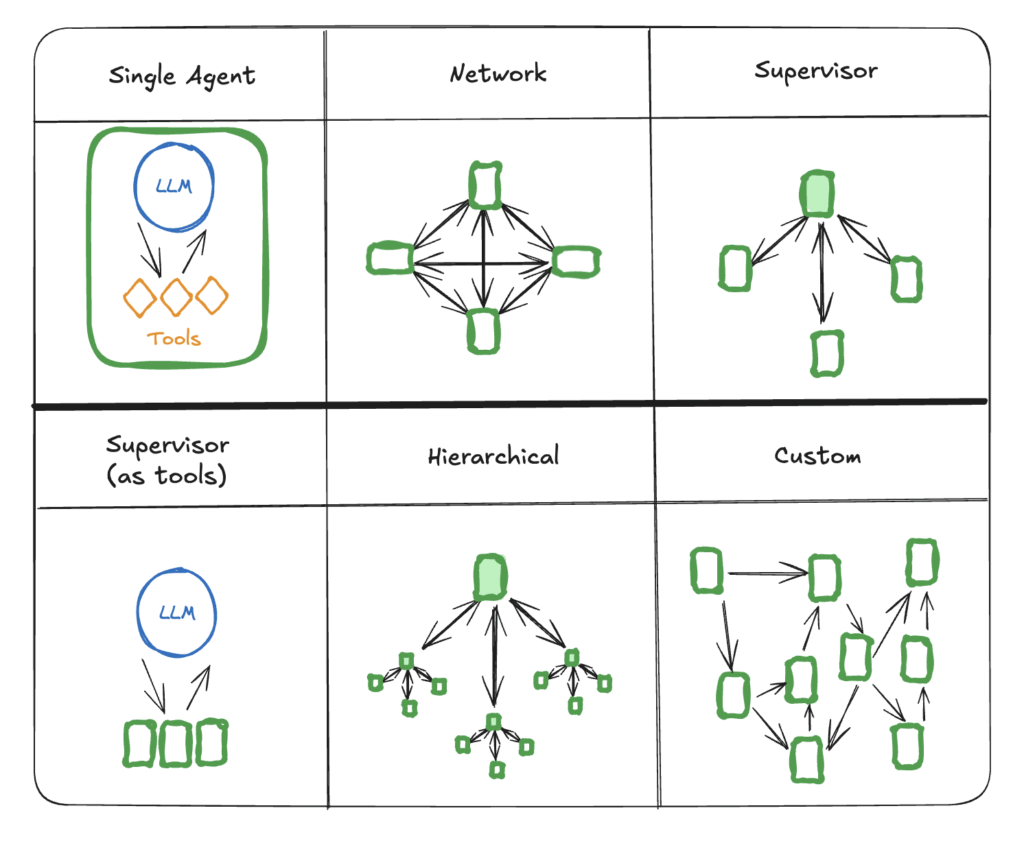
Source: https://langchain-ai.github.io/langgraph/concepts/multi_agent/
These multi-agent systems are designed to solve complex tasks by continuously analyzing and adapting their input and output data. Today, most setups rely on large language models to draft execution plans and mediate communication among agents. However, as mentioned earlier, a major limitation of LLMs is their tendency to hallucinate. That is also why most chat interfaces include a note saying that responses might be incorrect.
Imagine the flight-booking agent might schedule a trip to Paris, Texas, when the user wanted Paris, France. A quality-assurance agent might catch that kind of mistake, but there is no guarantee it will. With extra safeguards or hardcoded failsafes, you might catch a mistake like this. However, since these models rely on probabilities, they could produce a different kind of error in each new booking. These errors can lead to real-world consequences. The more freedom AI agents have to act on their own, the higher the chance that something will go wrong eventually. This is why many of these systems are still considered proof of concept or rely heavily on human agents for corrections. For many companies, the risk of losing customers or damaging their reputation is simply too high.
In my view, there is currently no effective solution to this problem. A recent research paper formally described the issue and suggested that it may not be possible to eliminate hallucinations entirely. This aligns with both my own experiments and how the market has evolved over the past two years; regardless of the method used, hallucinations have remained a major issue. I believe a true solution will require a new kind of model architecture.
For now, the community is exploring Agentic workflows to limit the degree of freedom of AI agents and integrate them efficiently within process flows to generate business value. While I don’t believe this will solve the hallucination problem, it does make it more manageable. This approach is likely to stay, because if a more reliable model is developed in the future, it can simply replace the existing one within the same structured workflow.
To run a workflow, a business process is divided into clearly defined, atomic tasks. One of these tasks might require an AI agent to handle flexible input efficiently. Instead of writing a long list of if-statements for every possible case, an AI agent can interpret the data and decide which execution strategy to follow. Since the agent is only responsible for one step at a time, its freedom is limited, and a human can review the output after each step if needed.
This way of integrating AI into existing workflows is, in my opinion, where we are heading in the near future. There is no reason to give AI full control over an entire process chain and risk hallucinations when most of it already follows pre-defined steps. n8n currently offers a solution for embedding AI agents into process flows, and I think they are definitely worth exploring (https://n8n.io). So far, they are the only platform I’ve seen directly addressing this specific challenge. However, I suspect more players are starting to enter the space. Popular orchestrators like Airflow already support AI agents; Dagster and Orchestra are likely to adopt similar capabilities soon.
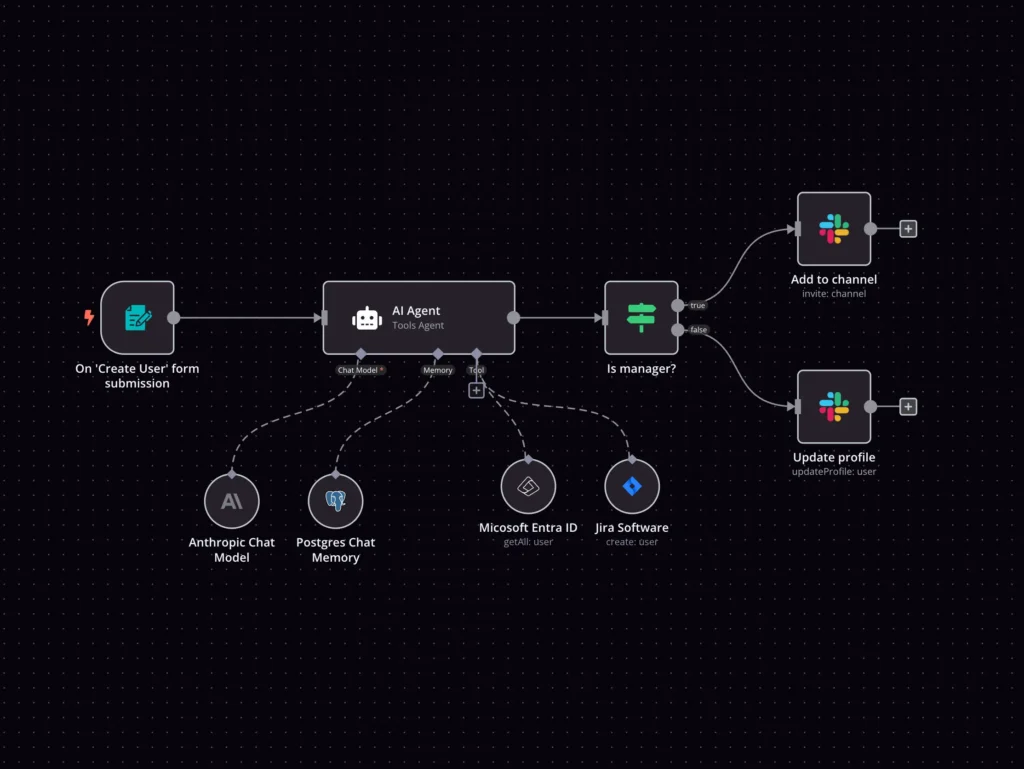
Source: https://n8n.io/
New terms and concepts appear almost every week, which makes it hard to stay up to date with the latest developments. In my experience, many innovations happen in similar areas and are not truly groundbreaking. Most progress involves finding new ways to organize agentic systems or improving specific parts to perform better on certain benchmarks.
However, benchmarks are not always a good way to measure how well a system works in real-world situations. This is especially true when it is unclear how the models were trained or what data was used during training or augmentation.
One benchmark that stands out is ARC. It was recently updated with a new version called ARC-AGI 2. François Chollet, the developer of Keras, designed ARC to test AI on tasks that are easy for humans but difficult for machines. It focuses on grid-based pattern recognition, where an AI or a human must understand examples and apply the same transformation logic to new cases.
The pace of innovation is still incredibly fast. We continue to see major improvements every three to six months, such as OpenAI’s recent advances in image generation. On the programming side of AI agents, some of the latest developments include the Model Context Protocol (MCP) and the Agent2Agent (A2A) Protocol.
MCP is like a USB-C port for AI models. It provides a universal way to connect with different tools and data sources. Through a simple client-server setup, MCP clients manage communication while modular servers provide access to services like email, calendars, or local files. This makes it easy to build secure, flexible, and context-aware AI systems without the hassle of separate integrations.
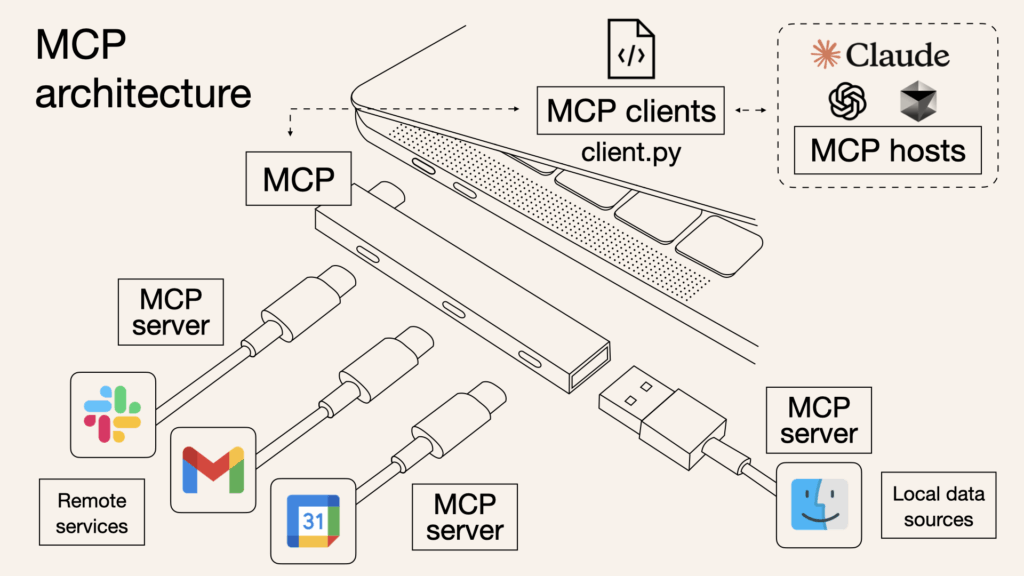
Source: https://www.claudemcp.com/blog/mcp-vs-api
A2A is an open protocol that enables AI agents to discover each other’s capabilities, exchange tasks, and collaborate securely across platforms. A client agent initiates a task while a remote agent performs it, with both exchanging messages that include context, progress updates, and outputs.
New protocols are continuously being introduced, though it remains to be seen which will stand the test of time. Let’s take a closer look at some key characteristics of today’s market.
I think we have different layers where companies are trying to offer solutions to build agentic systems. The model layer is highly competitive, dominated by a few key players such as OpenAI, Anthropic, Mistral, and DeepSeek, along with major tech corporations like Facebook, Google, and Microsoft. This landscape leaves limited market opportunity for new entrants to gain traction without access to substantial GPU and electricity resources.
At the agentic orchestration level, notable players such as LangGraph, AWS multi-agent orchestrator, and Microsoft Autogen are beginning to implement the agent patterns discussed. However, these frameworks are still in the early stages of development, as indicated by their version numbers, which suggests there is room for variability and new entrants.
The application layer is a wild area where numerous companies emerge and disappear rapidly, since a simple API wrapper might be obsolete within weeks when newer LLM features appear. It is hard to predict which applications will endure in the long run.
In the database sector, while there are many dedicated vector databases available, I don’t believe this will be a long-lasting market since many major vendors have also added support for vector search in their database environments. Additionally, knowledge graph databases are gaining traction due to their improved accuracy and ability to attach semantic meaning to company data. There have been big changes in the knowledge graph market, especially with the merger of Ontotext and Semantic Web Company to create Graphwise and the recent acquisition of data.world by ServiceNow. The market is reacting to the growing demand for more accurate, semantically rich data. As said before, context remains king.
The process orchestration layer is relatively new and provides an easy way to integrate AI agents into existing business processes. I believe such orchestration engines will be key in the coming years, especially given the need to constrain the agents’ decision-making freedom to achieve reliable and consistent results.
Generally, I believe the market is currently overhyped and that too much investment has been made in a technology that still fails to deliver the expected business impact. Only a few companies can truly harness the power of LLMs, as they tend to operate in content-centric industries where models can be used more or less out of the box. Additionally, there is still no consensus on copyright issues, as seen when CD Project RED dismissed using AI for graphic assets due to concerns about legal liability. Even if it were legally safe, marketers seem to underestimate the critical role of human input in this transition, since authenticity remains essential. On platforms like LinkedIn, where AI-generated posts are becoming the norm, the appreciation of an authentic post goes a long way nowadays.
Despite these challenges, I believe the core idea of agentic AI will continue to gain ground. Whether future AI systems are based on LLMS or new model architectures, it is essential to embed agents into business processes and ensure they can access the right context to complete specific tasks. Managing your data correctly and efficiently has always been and still is the fuel that keeps the AI engine running. Stay focused and take care of your data estate.
In my opinion, LLMs are currently great for building MVPs, creating PoCs, generating boilerplate code, and prototyping frontend components. However, they still struggle with production-grade systems that require complex architectures, deep domain logic, stringent security measures, and high performance. This underscores the need for human oversight, and I believe this won’t change for quite some time. The models will continue to improve, but I believe they will reach their limits within the next few years. This belief is based on recent statements made by Yann LeCun, a pioneer in artificial intelligence and Chief AI Scientist at Meta.
I believe the most important takeaway from this article is that to truly unlock the full potential of large language models and future AI technologies, it is essential to provide the right context. Context is king.
🔗 Links:
- How LLMs predict words: https://www.anthropic.com/research/tracing-thoughts-language-model
- Glue pizza and eat rocks: https://www.bbc.com/news/articles/cd11gzejgz4o
- A Benchmark Knowledge Graphs on LLM’S Accuracy: https://arxiv.org/pdf/2311.07509
- Advanced Retrieval RAG Strategies: https://neo4j.com/blog/developer/advanced-rag-strategies-neo4j/?utm_campaign=DeveloperBlog&utm_content=&utm_medium=&utm_source=LinkedIn&utm_justglobal=NA&__readwiseLocation=
- Damien Benveniste: https://www.linkedin.com/in/damienbenveniste/
- EdgeAI: https://learn.theaiedge.io/
- Agentic Flow: https://www.linkedin.com/posts/damienbenveniste_agentic-design-is-probably-the-next-paradigm-activity-7244748104573280256-DhCX?utm_source=share&utm_medium=member_desktop&rcm=ACoAACc9gmYBlqZps6AEJ3PjeFWYJf7T3Aa4_bg
- Agentic Design and LLM pipeline orchestration: https://www.linkedin.com/posts/damienbenveniste_planning-agents-activity-7248010485323726848-YeIT?utm_source=share&utm_medium=member_desktop&rcm=ACoAACc9gmYBlqZps6AEJ3PjeFWYJf7T3Aa4_bg
- Aurimas Griciūnas: https://www.linkedin.com/in/aurimas-griciunas/
- RAG explained: https://www.linkedin.com/posts/aurimas-griciunas_llm-ai-machinelearning-activity-7296134869338746881-w9aT?utm_source=share&utm_medium=member_desktop&rcm=ACoAACc9gmYBlqZps6AEJ3PjeFWYJf7T3Aa4_bg
- Hallucination is Inevitable: An Innate Limitation of Large Language Models: https://arxiv.org/abs/2401.11817
- Tune in on minute 17:00 Yann LeCun interview: https://youtu.be/qvNCVYkHKfg?si=2h40ZaAu6-A_O0g8
- AI Agnetic Process Orchestration: https://n8n.io/
- ARC-AGI 2: https://arcprize.org/arc-agi#arc-agi-2
- MCP: https://modelcontextprotocol.io/introduction
- A2A: https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
- Airflow Agent Orchestration: https://github.com/astronomer/airflow-ai-sdk
- CD-Projekt Red: https://www.pcgamer.com/games/the-witcher/cd-projekt-says-its-not-using-generative-ai-on-the-witcher-4-because-its-quite-tricky-when-it-comes-to-legal-ip-ownership/
- Semantic Web Company and Ontotext Merger: https://semantic-web.com/swc-ontotext-merger-graphwise/
- ServiceNow and data.world: https://www.servicenow.com/company/media/press-room/workflow-data-fabric-ai-agents.html
Leave a Reply